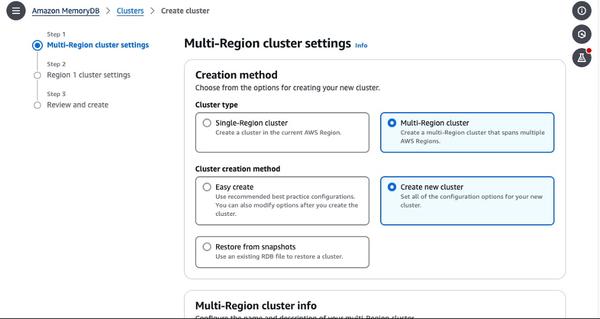
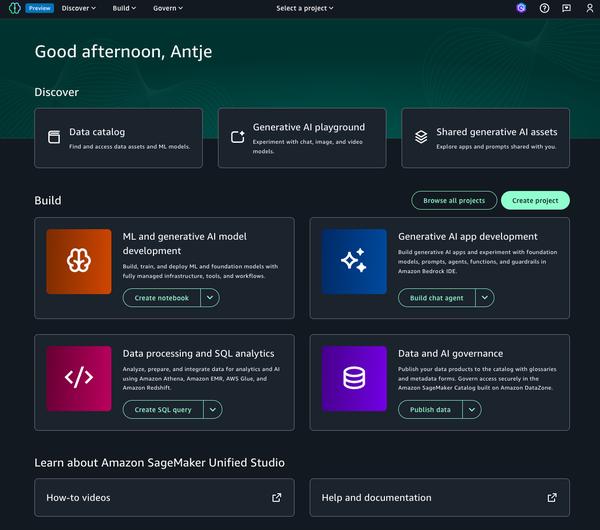
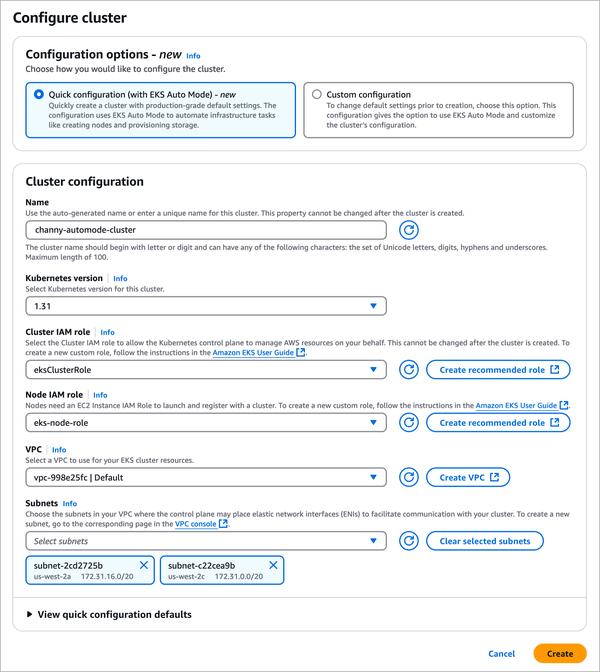
Google ha publicado una entrada de blog sobre el ajuste fino de grandes modelos lingüísticos, centrándose en Gemma. El artículo ofrece una visión general del proceso de principio a fin, comenzando por la preparación del conjunto de datos y pasando por el ajuste fino de un modelo ajustado a las instrucciones.
Me pareció especialmente interesante cómo enfatizaban la importancia de la preparación de datos y la optimización de hiperparámetros. Está claro que estos aspectos pueden tener un impacto significativo en el rendimiento del modelo, y es esencial considerarlos cuidadosamente.
Un reto que veo a menudo en mi trabajo es asegurar que los chatbots entiendan el lenguaje matizado, manejen diálogos complejos y ofrezcan respuestas precisas. El enfoque descrito en esta entrada del blog parece ofrecer una solución prometedora a este problema.
Me interesaría saber más sobre los detalles del proceso de ajuste de hiperparámetros. Por ejemplo, ¿qué parámetros específicos se ajustaron y cómo se determinaron los valores óptimos? Una discusión más profunda de este aspecto sería muy útil.
En general, esta entrada del blog me ha parecido muy informativa y ofrece una útil visión general del ajuste fino de grandes modelos lingüísticos. Creo que esta información será valiosa para cualquiera que desee crear chatbots u otras aplicaciones basadas en el lenguaje.