Amazon anunció la disponibilidad de la Destilación de Modelos de Amazon Bedrock en vista previa, que automatiza el proceso de creación de un modelo destilado para su caso de uso específico generando respuestas de un modelo de base grande (FM) llamado modelo maestro y ajustando un FM más pequeño llamado modelo estudiante con las respuestas generadas. Utiliza técnicas de síntesis de datos para mejorar la respuesta del modelo maestro. Amazon Bedrock luego aloja el modelo destilado final para la inferencia, brindándole un modelo más rápido y rentable con una precisión cercana al modelo maestro, para su caso de uso. Estoy realmente impresionado con esta nueva característica. Creo que será muy útil para los clientes que buscan utilizar modelos de IA generativa pero les preocupa la latencia y el costo. Al destilar un modelo grande en uno más pequeño, los clientes pueden reducir la latencia y el costo mientras mantienen la precisión. Creo que esta característica será un cambio de juego en el campo de la IA generativa.
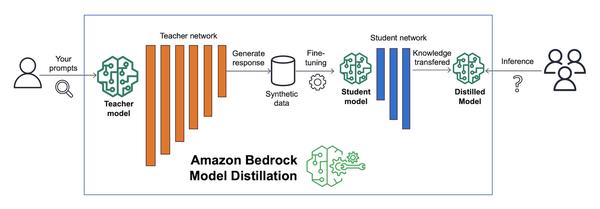
Crea modelos más rápidos, rentables y de alta precisión con Amazon Bedrock Model Distillation (vista previa)
AWS