Google Cloud publicó una entrada de blog sobre "Ahorre en GPU: escalado automático más inteligente para sus cargas de trabajo de inferencia de GKE". El artículo analiza cómo la ejecución de cargas de trabajo de inferencia de modelos LLM puede ser costosa, incluso cuando se utilizan los modelos y la infraestructura abiertos más recientes.
Una solución propuesta es el escalado automático, que ayuda a optimizar los costes al garantizar que se satisfaga la demanda de los clientes y que solo se pague por los aceleradores de IA que se necesitan.
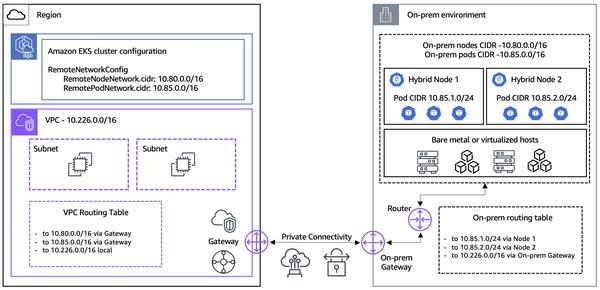
El artículo proporciona orientación sobre cómo configurar el escalado automático para cargas de trabajo de inferencia en GKE, centrándose en la elección de la métrica adecuada.
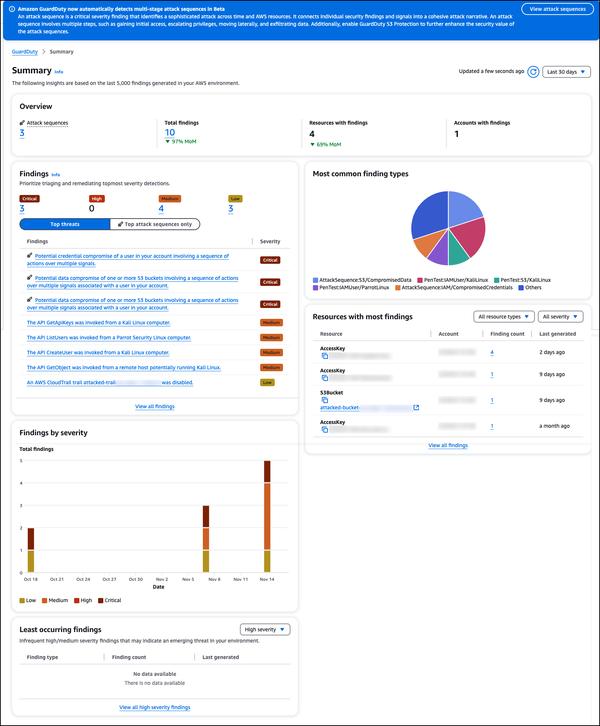
Me pareció especialmente interesante comparar las distintas métricas para el escalado automático en GPU, como el uso de la utilización de la GPU frente al tamaño del lote frente al tamaño de la cola.
Descubrí que el uso de la utilización de la GPU no es una métrica eficaz para el escalado automático de cargas de trabajo de LLM porque puede dar lugar a un exceso de aprovisionamiento. Por otro lado, el tamaño del lote y el tamaño de la cola proporcionan indicadores directos de la cantidad de tráfico que está experimentando el servidor de inferencia, lo que las convierte en métricas más eficaces.
En general, el artículo proporcionó una útil visión general de cómo optimizar el rendimiento de costes de las cargas de trabajo de inferencia de LLM en GKE. Recomiendo leer el artículo a cualquiera que desee desplegar cargas de trabajo de inferencia de LLM en GKE.