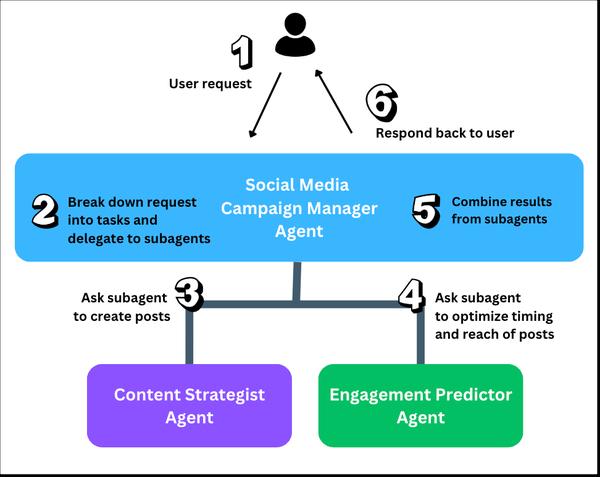
Amazon Data Firehose presenta una nueva capacidad para capturar cambios de bases de datos como PostgreSQL, MySQL y replicar actualizaciones a tablas Apache Iceberg en Amazon S3. Esto ofrece una solución simple de extremo a extremo para la transmisión de actualizaciones de bases de datos sin afectar el rendimiento de las transacciones. Los usuarios pueden configurar un flujo de Data Firehose en minutos para entregar actualizaciones de captura de datos de cambio (CDC) desde sus bases de datos. Ahora pueden replicar fácilmente datos de diferentes bases de datos en tablas Iceberg en Amazon S3 y utilizar datos actualizados para análisis a gran escala y aplicaciones de aprendizaje automático (ML). Los clientes empresariales de AWS suelen utilizar cientos de bases de datos para aplicaciones transaccionales. Para realizar análisis a gran escala y ML en los datos más recientes, desean capturar los cambios realizados en las bases de datos, como cuando se insertan, modifican o eliminan registros en una tabla, y entregar actualizaciones a su almacén de datos o lago de datos de Amazon S3 en formatos de tabla de código abierto como Apache Iceberg. Muchos clientes desarrollan trabajos de extracción, transformación y carga (ETL) para leer periódicamente desde bases de datos. Sin embargo, los lectores ETL afectan el rendimiento de las transacciones de la base de datos y los trabajos por lotes pueden agregar horas de retraso antes de que los datos estén disponibles para el análisis. Para mitigar esto, los clientes desean transmitir los cambios realizados en la base de datos, lo que se conoce como un flujo CDC. Con esta nueva capacidad de transmisión de datos, Data Firehose agrega la capacidad de adquirir y replicar continuamente flujos CDC desde bases de datos a tablas Apache Iceberg en Amazon S3. Los usuarios configuran un flujo de Data Firehose especificando el origen y el destino. Data Firehose captura y replica una instantánea de datos inicial y todos los cambios posteriores en las tablas de la base de datos seleccionadas como un flujo de datos. Para adquirir flujos CDC, Data Firehose utiliza el registro de replicación de la base de datos, lo que reduce el impacto en el rendimiento de las transacciones de la base de datos. Cuando el volumen de actualizaciones de la base de datos fluctúa, Data Firehose particiona automáticamente los datos y conserva los registros hasta la entrega. Los usuarios no necesitan aprovisionar capacidad ni administrar clústeres. Data Firehose también puede crear automáticamente tablas Apache Iceberg utilizando el mismo esquema que las tablas de la base de datos durante la creación inicial del flujo y desarrollar automáticamente el esquema de destino en función de los cambios del esquema de origen. Como servicio totalmente administrado, Data Firehose elimina la necesidad de componentes de código abierto, actualizaciones de software o gastos generales operativos.
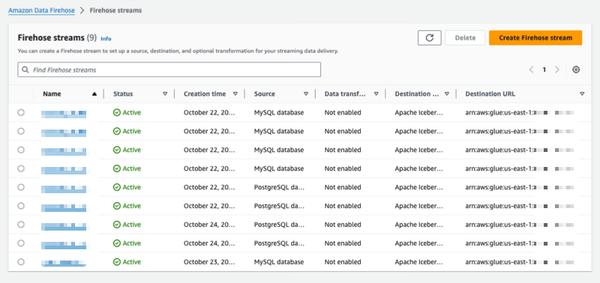
Replicar cambios de bases de datos a tablas Apache Iceberg usando Amazon Data Firehose (en vista previa)
AWS