Amazon Bedrock ha anunciado nuevas capacidades de evaluación RAG y LLM como juez, lo que agiliza las pruebas y la mejora de las aplicaciones de IA generativa. Las bases de conocimiento de Amazon Bedrock ahora admiten la evaluación RAG, lo que le permite ejecutar una evaluación automática de la base de conocimiento para evaluar y optimizar las aplicaciones de generación aumentada por recuperación (RAG). Esto utiliza un modelo de lenguaje grande (LLM) para calcular las métricas de evaluación, lo que permite la comparación de diferentes configuraciones y el ajuste para obtener resultados óptimos. La evaluación del modelo de Amazon Bedrock ahora incluye LLM como juez, lo que permite probar y evaluar otros modelos con calidad similar a la humana a una fracción del costo y el tiempo. Estas capacidades proporcionan una evaluación rápida y automatizada de las aplicaciones de IA, acortando los ciclos de retroalimentación y acelerando las mejoras. Las evaluaciones evalúan las dimensiones de calidad como la corrección, la utilidad y los criterios de IA responsable, como el rechazo de respuestas y la nocividad. Los resultados proporcionan explicaciones en lenguaje natural para cada puntaje, normalizadas de 0 a 1 para una fácil interpretación. Las rúbricas y las indicaciones del juez se publican en la documentación para mayor transparencia.
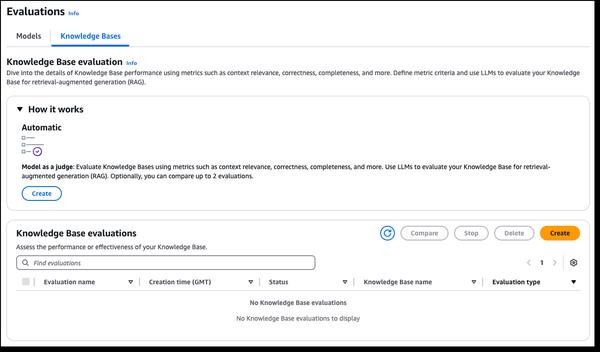
Nuevas capacidades de evaluación RAG y LLM como juez en Amazon Bedrock
AWS