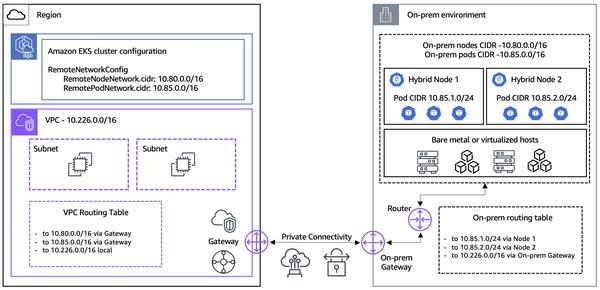
Yahoo publicó recientemente un caso de estudio que compara el costo y el rendimiento de ejecutar Apache Flink y Google Cloud Dataflow para canalizaciones de datos a gran escala. El estudio descubrió que Dataflow es entre 1,5 y 2 veces más rentable que Apache Flink autogestionado para sus casos de uso probados.
Un aspecto interesante del estudio es cómo destacó la importancia de Dataflow Streaming Engine para impulsar la optimización de costos. Streaming Engine descarga gran parte del cálculo pesado al backend de Dataflow, lo que reduce la cantidad de vCPU necesarias en los trabajadores de Dataflow. Esto da como resultado una menor utilización de recursos y, en consecuencia, menores costos.
Además, el estudio enfatizó la importancia de una configuración cuidadosa y una experimentación continua al optimizar las canalizaciones de Dataflow. Se descubrió que el modelo de facturación basado en recursos, en particular, es muy eficaz para optimizar los costos de las cargas de trabajo basadas en el rendimiento.
En general, el caso de estudio de Yahoo proporciona información valiosa para las organizaciones que buscan optimizar sus canalizaciones de datos a gran escala. Al destacar los beneficios de ahorro de costos de Dataflow, especialmente cuando se combina con Streaming Engine y el modelo de facturación basado en recursos, presenta un caso convincente para que las empresas consideren Dataflow para sus necesidades de procesamiento de datos.